2
Uncertainty in Measurement
▼
Quantifying Uncertainty in Laboratory Instruments

Different laboratory instruments inherently possess varying levels of uncertainty, which must be accounted for when reporting measurements. For instruments with an analogue scale, such as a graduated cylinder or a thermometer, the uncertainty is typically estimated as plus or minus (±) half of the smallest division marked on the scale. This acknowledges that a reading can reasonably fall anywhere within that half-division range.
In contrast, for digital scales, the last reported digit is considered uncertain. The uncertainty for a digital instrument is generally taken as plus or minus (±) the smallest scale division that the instrument can display. This means if a digital balance reads to two decimal places, its uncertainty would be ±0.01 units.


When reporting measurements, it is crucial to ensure that the precision of the reported value aligns with its associated uncertainty. For example, a measurement reported as 41.9 ± 0.5 mL indicates that the measurement is precise to the tenths place, consistent with the uncertainty. Similarly, 1.40 ± 0.05 mL is reported to the hundredths place, matching the uncertainty. A highly precise measurement like 100.00 ± 0.01 g is reported to the hundredths place, reflecting the very small uncertainty. It is also important to remember specific techniques for reading certain instruments, such as reading from the bottom of the meniscus for liquid volumes in glassware.
Acknowledging Non-Quantifiable Uncertainties

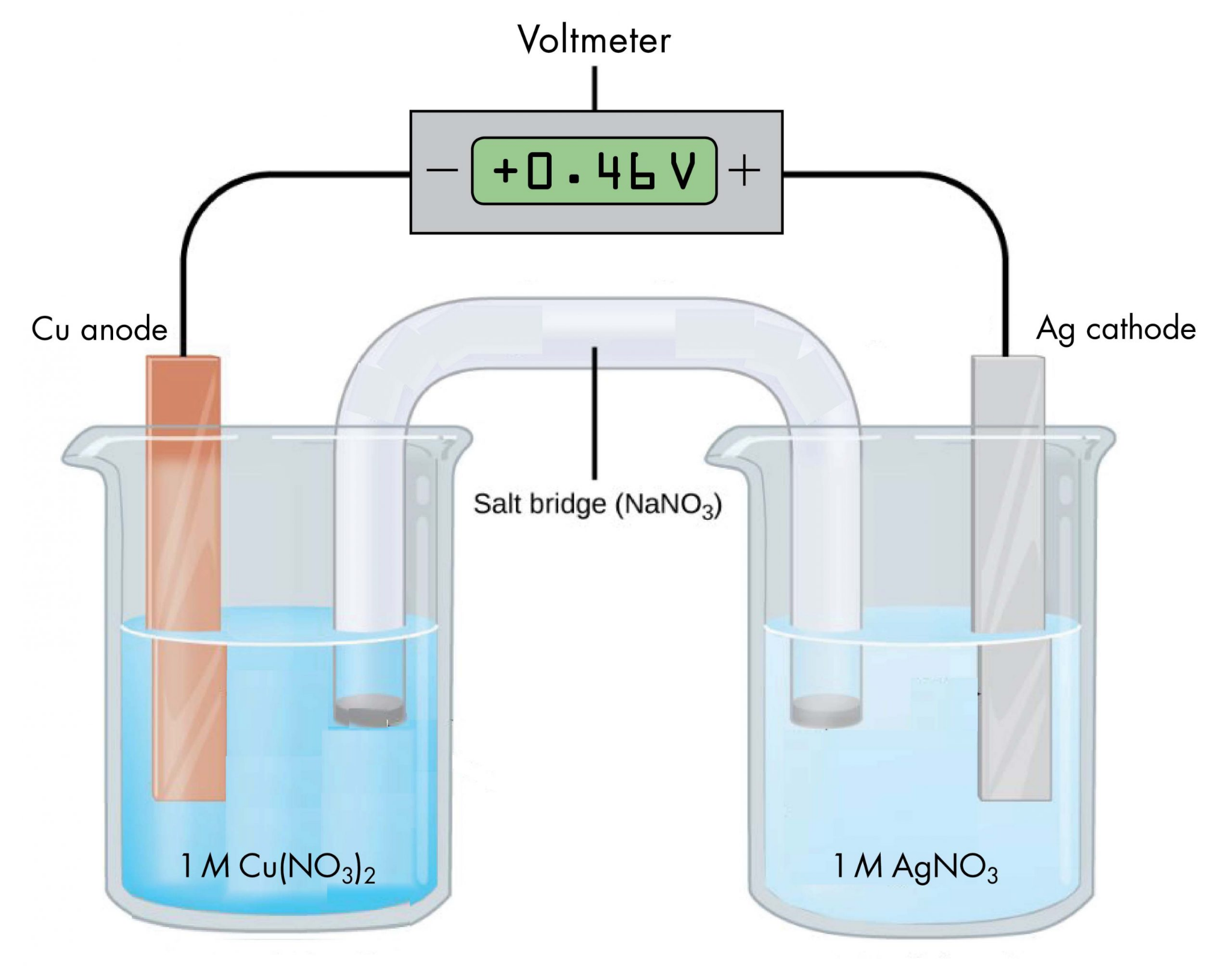
Beyond the inherent uncertainties of measuring instruments, other factors can introduce variability into experimental results. It is important to acknowledge all sources of uncertainty, even those that may not be easily quantifiable. These can include variations in time measurements, subjective interpretations such as changes in indicator colors during titrations, fluctuations in voltages of electrochemical cells, or temperature variations during thermodynamic reactions. While these may not always be expressed with a numerical ± value, their potential impact on the accuracy and precision of the experiment should be noted in any comprehensive analysis.

3
Significant Figures
▼
Understanding Uncertainty Through Significant Figures
Significant figures are crucial in scientific measurements as they convey the degree of uncertainty associated with a reported value. They represent all the digits in a measurement that are known with certainty, plus the first digit that is estimated or uncertain. It is essential to remember that all measurements must always be accompanied by appropriate units to provide context and meaning to the numerical value.The Role of Scientific Notation in Reporting Significant Figures
When reporting measurements, especially those with many zeros, scientific notation becomes an invaluable tool for clearly indicating the correct number of significant figures. This method eliminates ambiguity regarding the significance of trailing zeros. For instance, a measurement of "1000 s" is ambiguous because the number of significant figures is unclear. However, expressing it in scientific notation, such as "1.000 × 10³ s", explicitly states that there are four significant figures, indicating a higher precision in the measurement. The following table illustrates how scientific notation clarifies the number of significant figures for a given measurement:| Measurement | Significant figures |
|---|---|
| 1000 s | Unspecified |
| 1 × 10³ s | 1 |
| 1.0 × 10³ s | 2 |
| 1.00 × 10³ s | 3 |
| 1.000 × 10³ s | 4 |
| Measurement | Significant figures |
|---|---|
| 0.45 mol dm⁻³ | 2 |
| 4.5 × 10⁻¹ mol dm⁻³ | 2 |
| 4.50 × 10⁻¹ mol dm⁻³ | 3 |
| 4.500 × 10⁻¹ mol dm⁻³ | 4 |
| 4.5000 × 10⁻¹ mol dm⁻³ | 5 |

4
Experimental Errors
▼
Categorization of Experimental Errors
Experimental errors, which are inevitable in any scientific measurement, can be broadly classified into two main categories: random errors and systematic errors. Understanding the distinction between these types of errors is crucial for evaluating the reliability of experimental results and for designing effective strategies to minimize their impact.
Understanding Random Errors
Random errors arise from unpredictable fluctuations in experimental conditions or from the inherent limitations of measurement. These errors have multiple potential causes, including subtle changes in the surrounding environment such as temperature variations or air currents, slight misinterpretations of measurement readings by the experimenter, or simply an insufficient amount of collected data. A defining characteristic of random errors is that they have an equal probability of causing a measurement to be either too high or too low relative to the true value. While individual random errors cannot be eliminated, their overall impact on the experimental outcome can be significantly reduced by repeating the experiment multiple times and averaging the results. This practice helps to cancel out the random fluctuations, leading to a more precise measurement.
The Nature of Systematic Errors
In contrast to random errors, systematic errors consistently bias measurements in one direction, meaning they will always make the result either too high or too low. These errors typically stem from flaws in the experimental design, the procedure followed, or the calibration of the instruments used. Because systematic errors are inherent to the experimental setup, simply repeating the experiment multiple times will not reduce them; the same error will be consistently reproduced. To mitigate systematic errors, the experimental design or procedure itself must be modified. A key indicator of a systematic error is a consistent difference between the recorded experimental value and the accepted literature value for a given quantity.
Ensuring Repeatability and Reproducibility
To assess the reliability of experimental data, it is considered good scientific practice to ensure both repeatability and reproducibility. Repeatability refers to the ability of the same experimenter, using the same equipment and conditions, to obtain consistent results when duplicating an experiment. Reproducibility, on the other hand, refers to the ability of different experimenters, using different equipment or in different laboratories, to obtain similar results when performing the same experiment. These practices help to identify and quantify the extent of random errors.
Consider an example where the mass of a piece of magnesium ribbon is measured multiple times, yielding the following results: 0.1234 g, 0.1232 g, 0.1233 g, 0.1234 g, 0.1235 g, and 0.1236 g. The average mass is calculated as (0.1234 + 0.1232 + 0.1233 + 0.1235 + 0.1236) / 5 = 0.1234 g. To express the uncertainty associated with these measurements, we can calculate the range of the data, which is the difference between the highest and lowest values (0.1236 g - 0.1232 g = 0.0004 g). The uncertainty is then half of this range, so 0.0004 g / 2 = 0.0002 g. Therefore, the average mass can be reported as 0.1234 ± 0.0002 g, indicating that the data spans a range of ±0.0002 g from the average. This uncertainty primarily reflects the impact of random errors on the precision of the measurement.
Identifying and Correcting Systematic Errors
Systematic errors, unlike random errors, consistently skew results in a particular direction. For instance, if the mass of a magnesium ribbon is measured several times, but the balance was not correctly zeroed, all readings would be consistently higher or lower than the true value. If the readings obtained were 0.1236 g, 0.1234 g, 0.1235 g, 0.1236 g, 0.1237 g, and 0.1238 g, and it was later discovered that the balance was consistently reading 0.0002 g too high, then all recorded values would be systematically inflated by that amount. The average mass would be (0.1236 + 0.1234 + 0.1235 + 0.1237 + 0.1238) / 5 = 0.1236 g, with an uncertainty of ± 0.0002 g. However, even with this precision, the result is inaccurate due to the systematic offset.
Common examples of systematic errors include:
• Incorrectly reading the volume of a liquid from the top of the meniscus instead of the bottom, leading to consistently higher volume readings.
• Consistently overshooting the endpoint in a titration, resulting in an overestimation of the volume of titrant delivered.
• Using instruments that have not been properly calibrated, causing all measurements to be consistently off by a certain amount.
The presence of a systematic error is primarily detected by its effect on the accuracy of an experiment, meaning how close the measured value is to the true or accepted value.
Distinguishing Accuracy from Precision
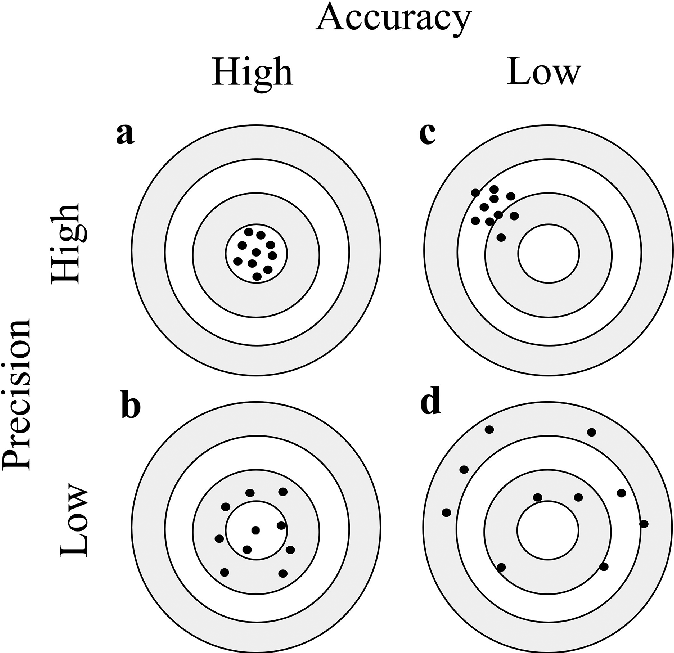
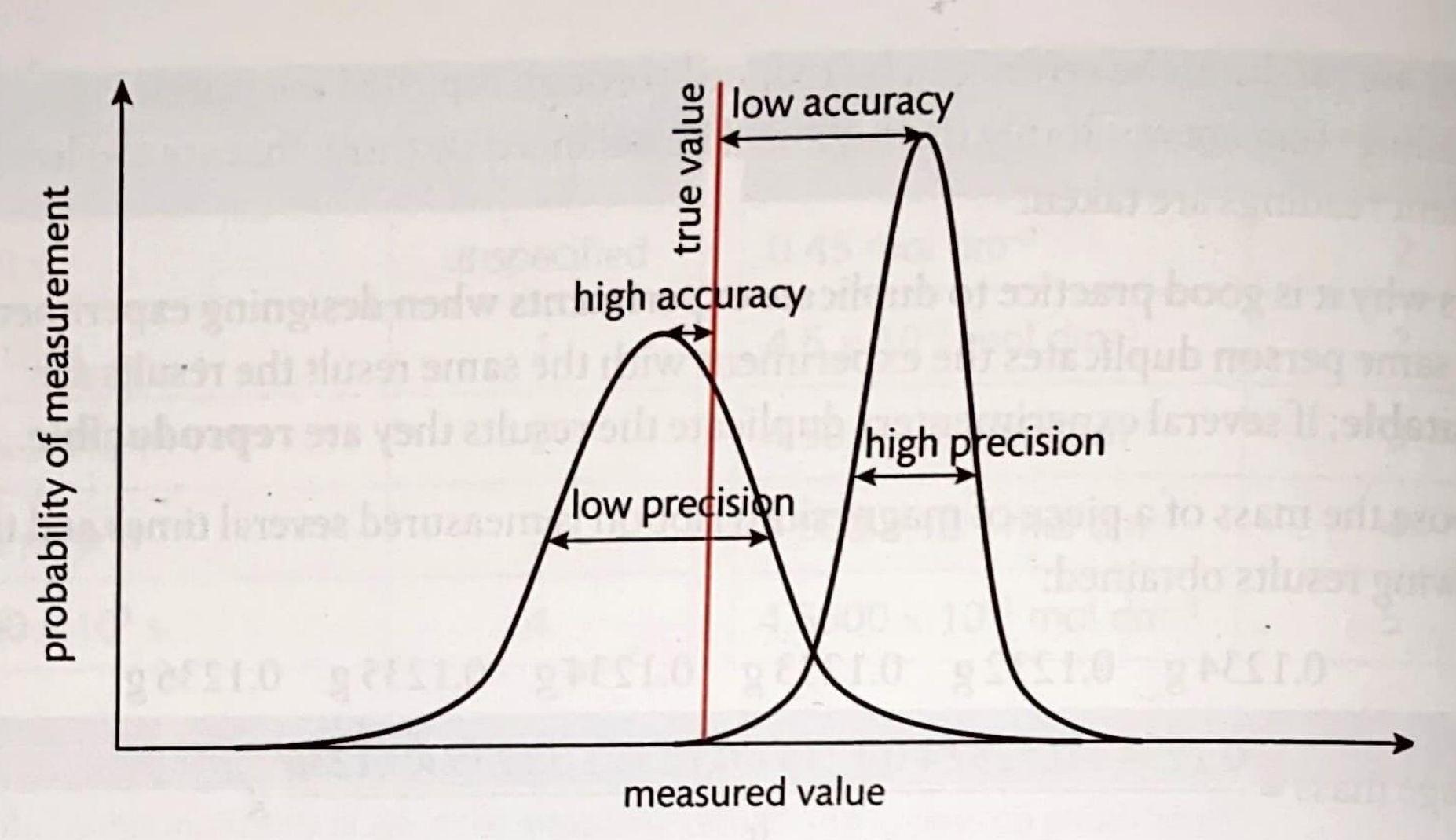
Accuracy and precision are two fundamental concepts in experimental measurements that are often confused but refer to distinct aspects of data quality. Accuracy describes how close a measured value is to the true or accepted value. A smaller systematic error directly leads to greater accuracy. Precision, on the other hand, refers to how close repeated measurements are to each other, regardless of their proximity to the true value. A smaller random error contributes to greater precision, indicating that the results are highly reproducible.
The relationship between accuracy and precision can be visualized as follows:
| Characteristic | Accuracy | Precision |
|---|---|---|
| Affected by | Systematic errors | Random errors |
| Definition | Closeness of a measurement to the accepted value | Closeness of repeated measurements to each other |
| Improvement method | Changing experimental design/procedure | Repeating experiments and averaging results |
9
How to Graph Data
▼
Fundamentals of Data Visualization in Chemistry
In chemistry, graphs are indispensable tools for visually representing and understanding the relationships between different variables. When constructing a graph, it is crucial to correctly identify and place the independent and dependent variables. The independent variable, which is the factor that is intentionally changed or controlled in an experiment, is always plotted on the x-axis. Conversely, the dependent variable, which is the factor that is measured or observed in response to changes in the independent variable, is always plotted on the y-axis.
For most chemical data, a scatter plot is the most appropriate type of graph, accounting for approximately 99% of graphical representations in the field. When setting up the axes, it is important to use even intervals, though different scales can be applied to the x and y axes to best represent the data. The goal is to ensure that the data points occupy the majority of the graph's space, maximizing clarity and readability.
To quantify the strength and direction of the relationship between variables, two key statistical measures are employed: the correlation coefficient (r) and the coefficient of determination (R2). The correlation coefficient (r) provides a numerical value that indicates both the magnitude and direction of the linear relationship between two variables. A value of r close to +1 or -1 signifies a strong linear relationship, while a value close to 0 indicates a weak or no linear relationship. For instance, an r value of 0.99 suggests a very strong positive linear correlation.
A trendline, also known as a line of best fit, is a visual representation of the general pattern and direction of the data points on a scatter plot. The equation of this trendline is particularly useful as it allows for both interpolation (estimating values within the range of the observed data) and extrapolation (predicting values outside the range of the observed data). The coefficient of determination (R2) further elaborates on the relationship by indicating the proportion of the variance in the dependent variable that can be explained by the independent variable. R2 values range from 0 to 1, with values closer to 1 suggesting that the independent variable accounts for a large portion of the variation in the dependent variable. Conversely, R2 values closer to zero imply that other uncontrolled variables or experimental error might be significantly contributing to the observed changes in the dependent variable.
| Volume (mL) | Mass (g) |
|---|---|
| 0.56 | 5.2 |
| 0.81 | 7.3 |
| 0.92 | 8.9 |
| 1.21 | 10.1 |
| 1.40 | 12.0 |
Interactive Data Analysis
For a more dynamic exploration of data plotting and analysis, an interactive whiteboard is available. This tool facilitates group discussions and allows for real-time manipulation and visualization of data sets.
Click the picture to go to the interactive whiteboard
Illustrative Examples of Correlation Types
Graphs can exhibit various types of correlations, each providing unique insights into the relationship between variables. A positive correlation indicates that as the independent variable increases, the dependent variable also tends to increase. Conversely, a negative correlation means that as the independent variable increases, the dependent variable tends to decrease. The strength of these correlations can be categorized as strong, moderate, or weak, depending on how closely the data points cluster around the trendline.
A strong correlation is characterized by very little variance in the dependent variable with respect to the independent variable, suggesting a robust relationship. A moderate correlation shows a noticeable but not extreme amount of variance, indicating a relationship that is present but less precise. Finally, a weak correlation implies a large amount of variance, suggesting a tenuous or inconsistent relationship between the variables.
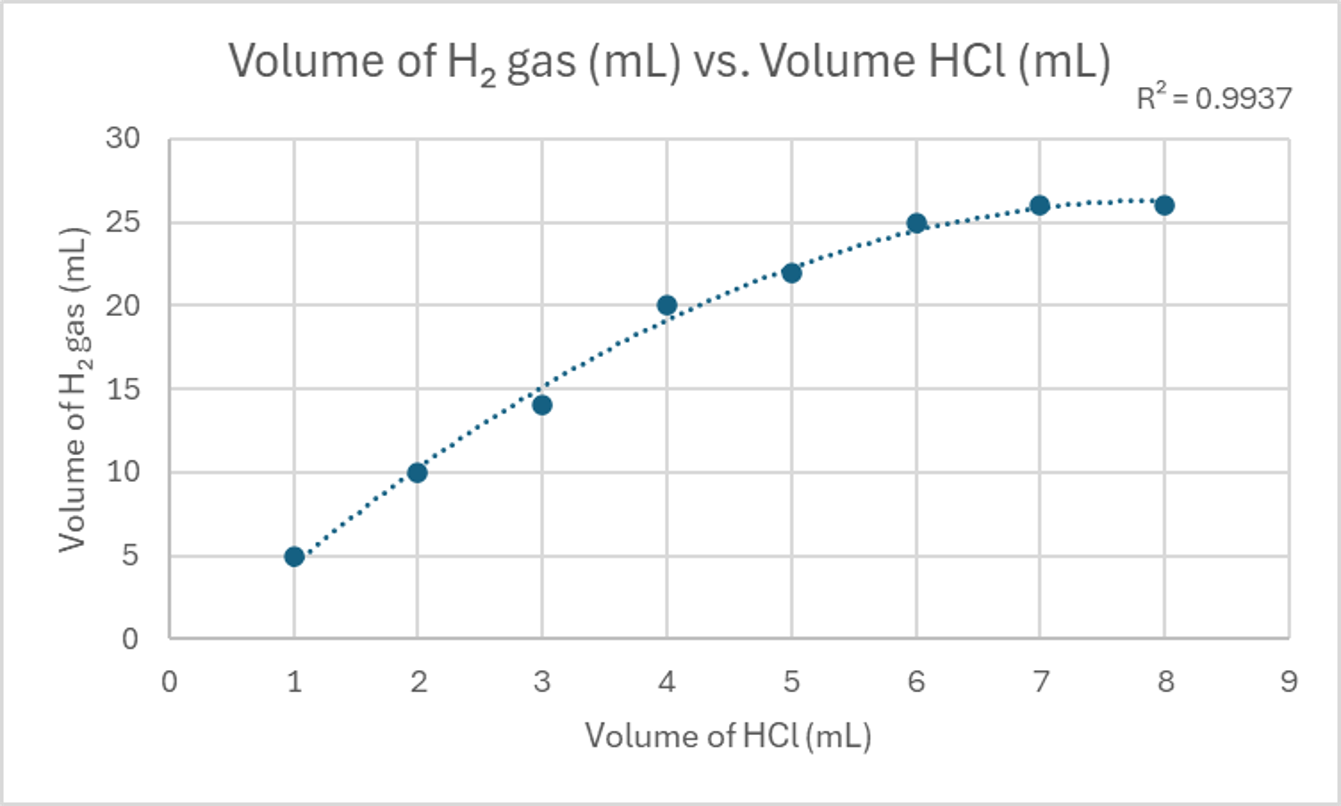
For instance, a strong, non-linear, positive correlation might be observed in a reaction where the product yield initially increases rapidly with temperature but then plateaus. A moderate, linear, positive correlation could be seen in a titration where the volume of reactant added directly corresponds to a steady increase in a measured property. The following tables provide data that can be used to visualize these different types of correlations.
| Volume of HCl (mL) | Volume of H₂ gas (mL) |
|---|---|
| 1 | 5 |
| 2 | 10 |
| 3 | 14 |
| 4 | 20 |
| 5 | 22 |
| 6 | 25 |
| 7 | 26 |
| 8 | 26 |
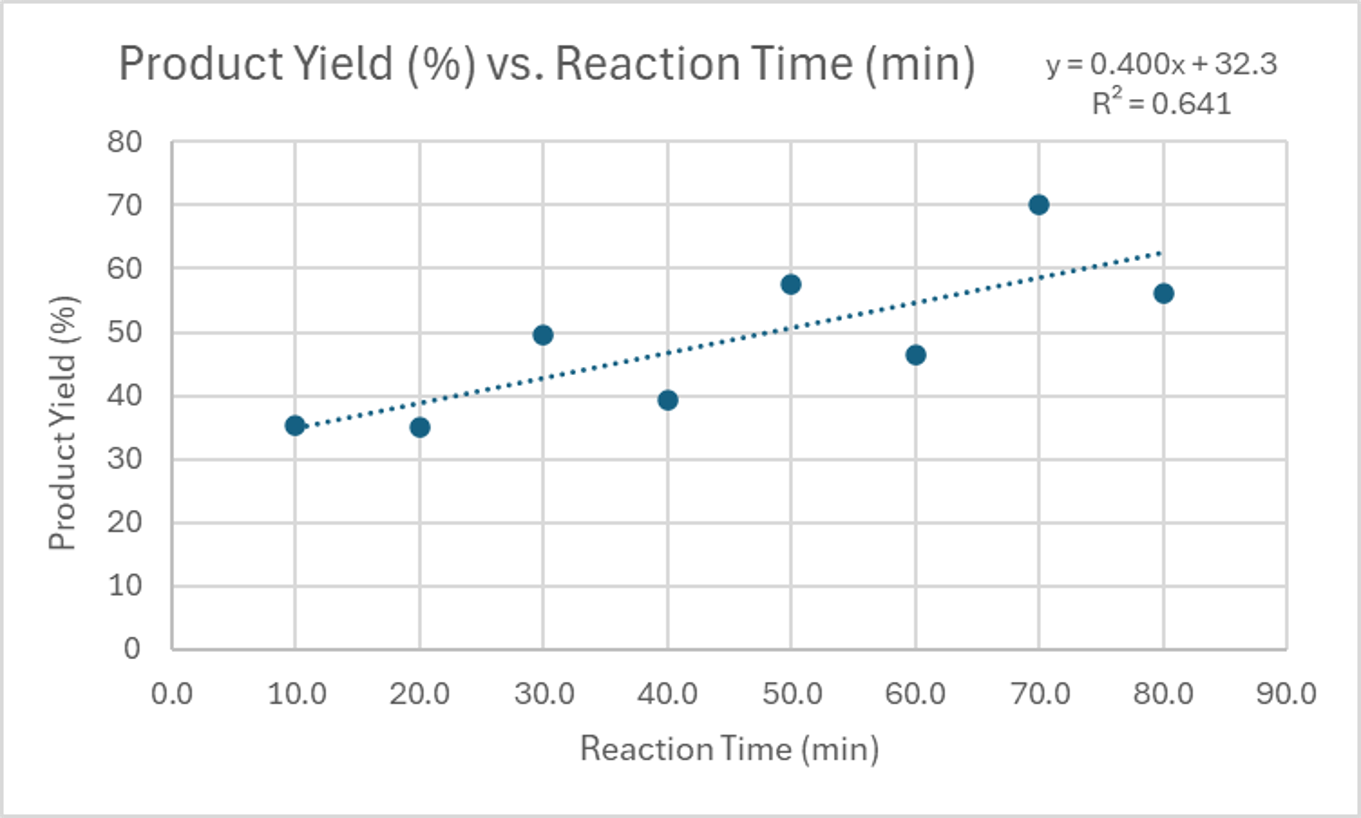
| Reaction Time (minutes) | Product Yield (%) |
|---|---|
| 10.0 | 35.2 |
| 20.0 | 35.1 |
| 30.0 | 49.5 |
| 40.0 | 39.4 |
| 50.0 | 57.5 |
| 60.0 | 46.5 |
| 70.0 | 70.1 |
| 80.0 | 56.2 |
Further Examples of Correlation Patterns
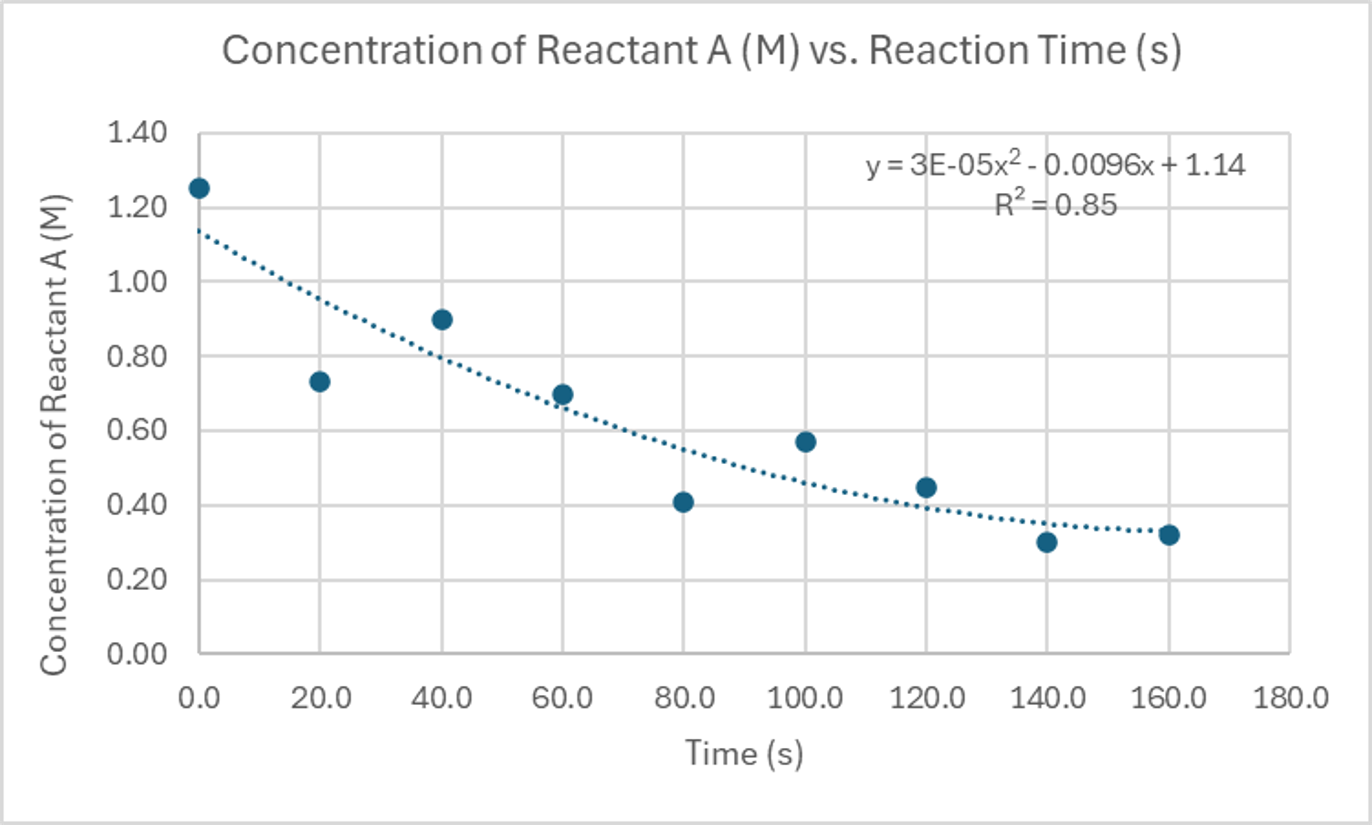
Continuing our exploration of correlation types, a strong, non-linear, negative correlation might be observed in a decay process where the concentration of a reactant decreases rapidly at first and then more slowly over time. A weak, negative correlation could be present in a scenario where an increase in one variable generally leads to a decrease in another, but with considerable scatter in the data points.
| Time (s) | Concentration of Reactant A (M) |
|---|---|
| 0.0 | 1.25 |
| 20.0 | 0.73 |
| 40.0 | 0.90 |
| 60.0 | 0.70 |
| 80.0 | 0.41 |
| 100.0 | 0.57 |
| 120.0 | 0.45 |
| 140.0 | 0.30 |
| 160.0 | 0.32 |
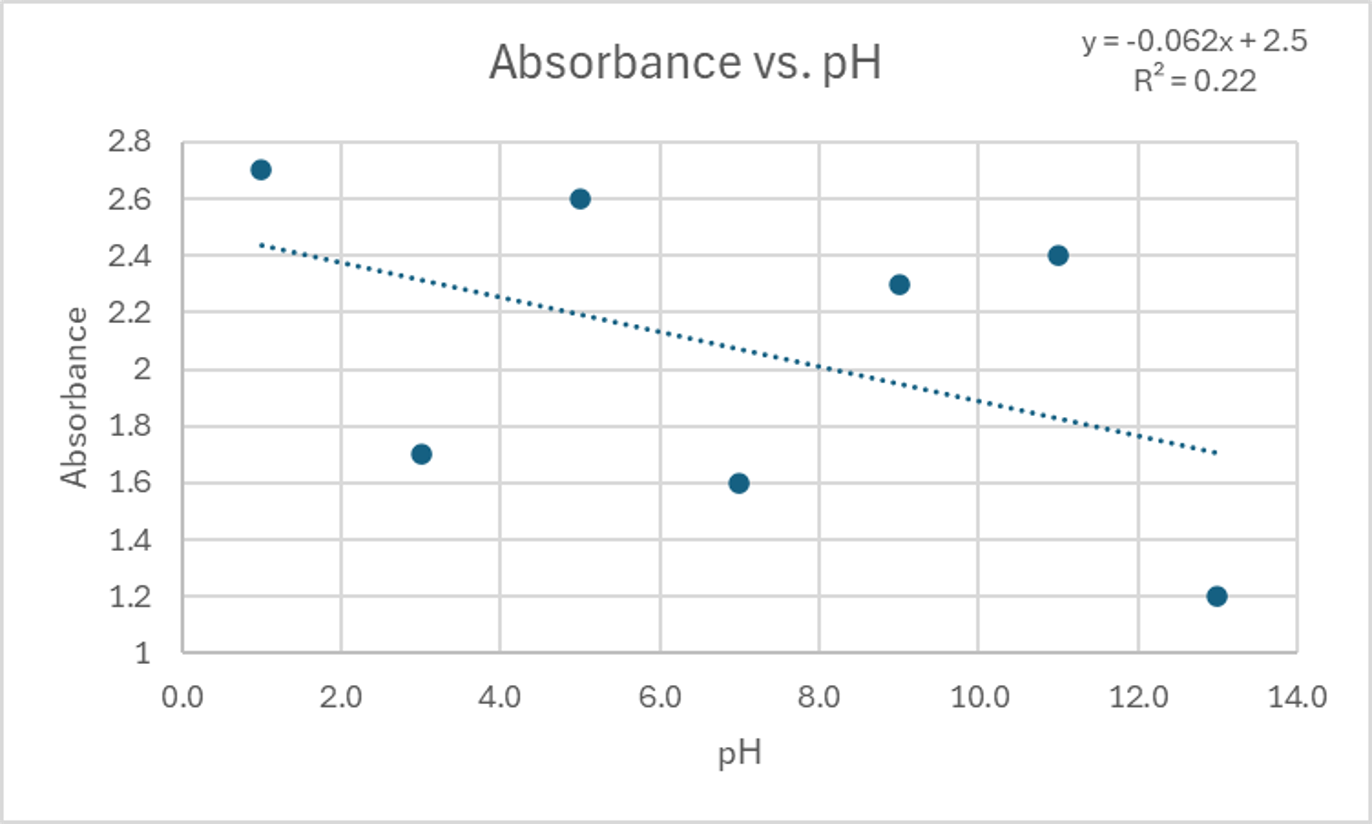
| pH | Absorbance |
|---|---|
| 1.0 | 2.7 |
| 3.0 | 1.7 |
| 5.0 | 2.6 |
| 7.0 | 1.6 |
| 9.0 | 2.3 |
| 11.0 | 2.4 |
| 13.0 | 1.2 |
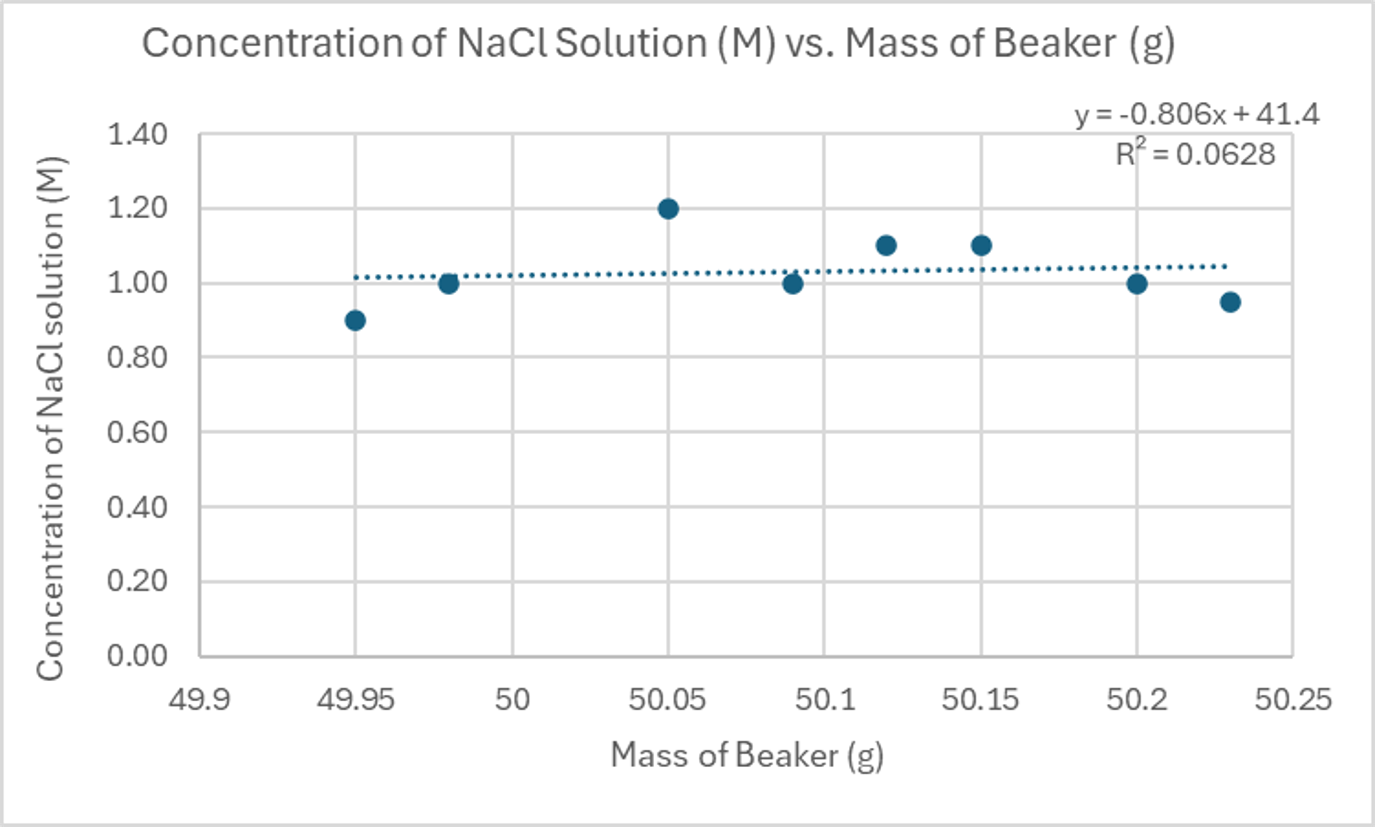
Distinguishing Between Moderate and No Correlation
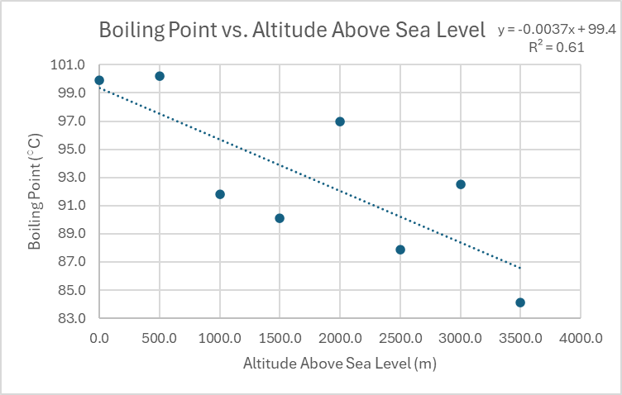
A moderate, linear, negative correlation would show a general downward trend as the independent variable increases, but with the data points not perfectly aligned along a straight line. In contrast, a scenario with no significant correlation implies that there is such a large amount of variance in the dependent variable that no discernible relationship with the independent variable can be established. In such cases, the data points appear randomly scattered, and a trendline would not accurately represent any underlying pattern.
| Altitude Above Sea Level (m) | Boiling Point (°C) |
|---|---|
| 0.0 | 99.9 |
| 500.0 | 100.2 |
| 1000.0 | 91.8 |
| 1500.0 | 90.1 |
| 2000.0 | 97.0 |
| 2500.0 | 87.9 |
| 3000.0 | 92.5 |
| 3500.0 | 84.1 |
| Mass of Beaker (g) | Concentration of NaCl Solution (M) |
|---|---|
| 49.95 | 0.90 |
| 49.98 | 1.00 |
| 50.05 | 1.20 |
| 50.09 | 1.00 |
| 50.12 | 1.10 |
| 50.15 | 1.10 |
| 50.2 | 1.00 |
| 50.23 | 0.95 |
Interpreting Correlation Coefficients
The correlation coefficient (r) is a quantitative measure that describes how strongly two variables are related to each other. Its value ranges from -1 to +1. A perfect correlation, either positive (+1) or negative (-1), indicates that all data points lie perfectly on a straight line. As the absolute value of r decreases towards 0, the strength of the correlation weakens.
While the boundaries between different correlation strengths can be subjective, a general rule of thumb for interpreting r values is as follows:• • • • •
- Perfect Correlation: r = +1 or r = -1
- Strong Correlation: r values typically between +0.8 and +1.0, or -0.8 and -1.0
- Moderate Correlation: r values typically between +0.4 and +0.8, or -0.4 and -0.8
- Weak Correlation: r values typically between +0.2 and +0.4, or -0.2 and -0.4
- No Correlation: r values close to 0 (e.g., between -0.2 and +0.2)
It is important to remember that a positive correlation means both variables increase or decrease together, while a negative correlation means one variable increases as the other decreases. The coefficient of determination (R2), which is the square of the correlation coefficient, provides further insight. R2 values closer to zero suggest that a significant portion of the variance in the dependent variable is not explained by the independent variable, implying that other uncontrolled variables or experimental error may be contributing factors. R2 values always range from 0 to 1.
10
Correlation vs. Causation & Data
▼
